原始問題
在共學群組中看到以下問題組,記錄一下閱讀 MDN 文件與 W3C 規格後的相關筆記 「pseudo-elements 是不是一個元素?」 「pseudo-elements 會出現在 DOM TREE 裡面嗎?」
回答
pseudo-elements 是不是一個元素?
- 不是,pseudo-elements 代表的是一個元素中的特定片段
- 將 pseudo-elements 作為 CSS 選取器使用時,它會選取某元素的指定部位,比如
::first-line代表選取某元素的第一行部位
pseudo-elements 會出現在 DOM TREE 裡面嗎?
- 不會,W3C level 1 已明確指出 pseudo-elements 與 pseudo-class 不存在於 HTML 中(do not exist in the HTML source, insert by the UA)
- DOM TREE 是瀏覽器讀取 HTML 原始碼後根據其內容生成,而 HTML 原始碼中並沒有 pseudo-elements,故不會出現在 DOM TREE 中(參考Constructing the Object Model)
筆記
MDN
- A CSS pseudo-class is a keyword added to a selector that specifies a special state of the selected element(s).
- A CSS pseudo-element is a keyword added to a selector that lets you style a specific part of the selected element(s).
level 1
- Pseudo-classes and pseudo-elements can be used in CSS selectors, but do not exist in the HTML source. Rather, they are “inserted” by the UA under certain conditions to be used for addressing in style sheets.
- They are referred to as “classes” and “elements” since this is a convenient way of describing their behavior. More specifically, their behavior is defined by a fictional tag sequence.
level 4
Pseudo-classes
- Pseudo-classes are simple selectors that permit selection based on information that lies outside of the document tree or that can be awkward or impossible to express using the other simple selectors.
- They can also be dynamic, in the sense that an element can acquire or lose a pseudo-class while a user interacts with the document, without the document itself changing.
- Pseudo-classes do not appear in or modify the document source or document tree.
Pseudo-elements
- Pseudo-elements represent abstract elements of the document beyond those elements explicitly created by the document language.
- A pseudo-element represents an element not directly present in the document tree. They are used to create abstractions about the document tree beyond those provided by the document tree.
- For example, pseudo-elements can be used to select portions of the document that do not correspond to a document-language element (including such ranges as don’t align to element boundaries or fit within its tree structure); that represent content not in the document tree or in an alternate projection of the document tree; or that rely on information provided by styling, layout, user interaction, and other processes that are not reflected in the document tree.
Constructing the Object Model
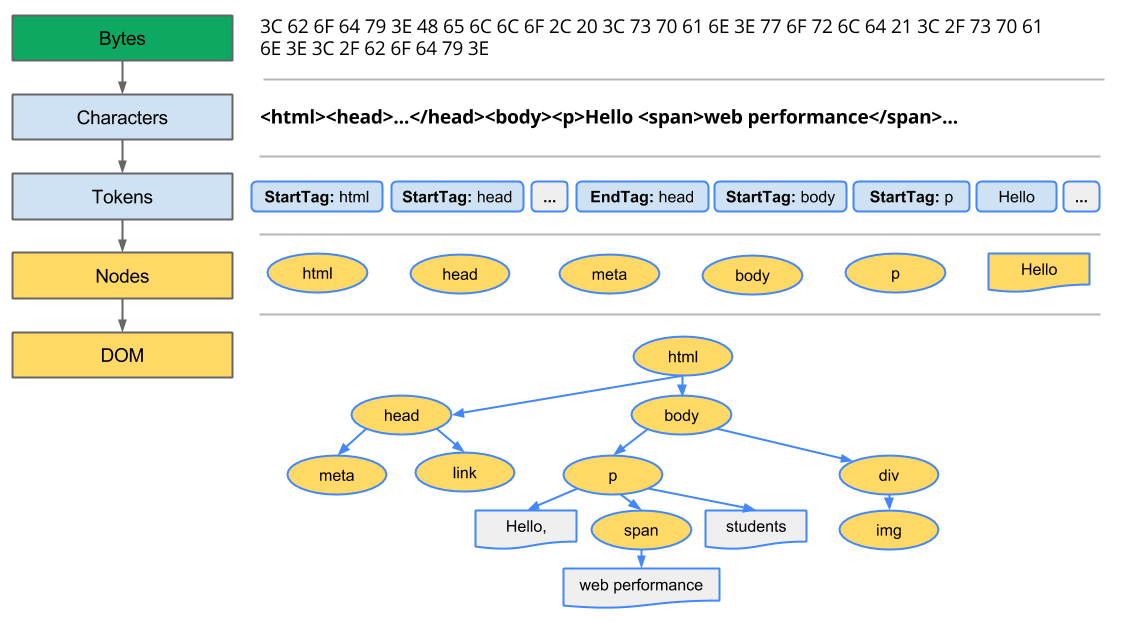
Every time the browser processes HTML markup, it goes through all of the steps below: convert bytes to characters, identify tokens, convert tokens to nodes, and build the DOM tree.
- Conversion: The browser reads the raw bytes of HTML off the disk or network, and translates them to individual characters based on specified encoding of the file (for example, UTF-8).
- Tokenizing: The browser converts strings of characters into distinct tokens—as specified by the W3C HTML5 standard; for example,
<html>,<body>—and other strings within angle brackets. Each token has a special meaning and its own set of rules. - Lexing: The emitted tokens are converted into “objects,” which define their properties and rules.
- DOM construction: Finally, because the HTML markup defines relationships between different tags (some tags are contained within other tags) the created objects are linked in a tree data structure that also captures the parent-child relationships defined in the original markup: the HTML object is a parent of the body object, the body is a parent of the paragraph object, and so on.