總結
此篇文章是 Good Code, Bad Code: Think like a software engineer 第四章(How to read complex code)的閱讀筆記。
本書認為看 code 時的困惑感共有三種類型(長期記憶中的知識不足、短期記憶過載、工作記憶過載),而此章的重點在如何減少「工作記憶過載」導致的困惑。手段如下:
- 反向重構:將程式碼重構為便於理解的結構
- 取代:將程式碼中不熟悉的語法換成自己熟悉的版本
- 透過依賴圖(dependency graph)以及狀態表(state table)來降低工作記憶的負荷
筆記
定義解釋
本書對於工作記憶(working memory)的定義為:大腦能思考、產生想法、解決問題的能力。
The working memory represents the brain’s capacity to think, to form new ideas, and to solve problems.
對本書作者來說短期記憶(short-term memory)與工作記憶是不同的能力。短期記憶用於「保存資訊」,而工作記憶的任務是「處理資訊」。
The role of the STM is to remember information. The role of the working memory, on the other hand, is to process information.
可參考下圖,同樣都是數字,圖左是使用短期記憶來記住一組電話號碼,而圖右是使用工作記憶來計算數字相加。
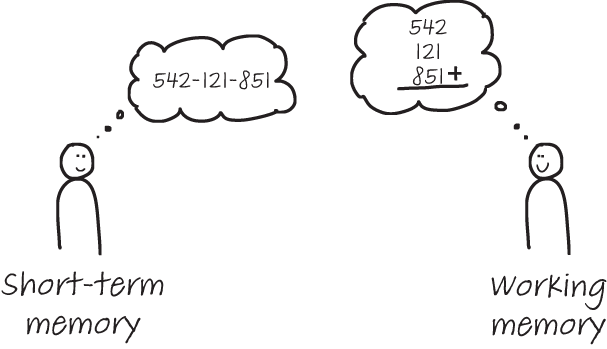
工作記憶也有上限,且上限與短期記憶相差不多,一般來說只能處理 2 到 6 組資訊。在閱讀且試圖「理解」該段程式碼時,如果程式碼無法被有效分塊,那麼工作記憶就會進入過載(overloaded)的狀況;困惑感即是源自於此。
認知負荷的種類
書中更近一步指出,認知負荷(cognitive load)還能在分為三種類型(同步參考維基百科):
- 內在(intrinsic):問題本身帶來的困難
- 外部(extraneous):不屬於問題本質,而是呈現方式引起的困難
- 密切的(germane):為了能將資訊保存到長期記憶(long-term memory)所需要的認知負荷
接下來要介紹的「減少工作記憶過載」方法主要針對「內在」與「外在」類型的負荷。
解決方式
反向重構
重構通常是將重複出現或是結構繁冗的程式碼整理成比較精簡、好維護的樣式。但這份精簡可能會讓對該份程式碼還不夠熟悉的開發者帶來理解困難。書中提到的「反向重構」則是與一般認知的重構反過來:為了理解方便,將那些整理到他處的程式碼直接複製一份到目前正在閱讀的檔案裡。
The goal of a cognitive refactoring is not to make the code more maintainable, but to make it more readable for the current reader at the current point in time.
取代
如果一個開發者對於某語言的掌握度還不是非常完善,在閱讀程式碼時,可考慮將那些還不熟悉的語法替換為自己比較熟悉的版本。
舉例:對一個剛開始接觸 JavaScript 的工程師來說,比起使用 Array.map() 來透過一個陣列產生另外一個陣列,使用 for (let i = 0; i < arr.length; i++) 搭配 Array.push() 來產生一個新陣列可能會「更好懂」。這就是「取代」。
依賴圖與狀態表
依賴圖(dependency graph):推薦將程式碼印到紙上來作業、或至少存成 PDF 格式搭配平板來進行標記。標記的方法是:圈選變數、功能,以及將出現多次的變數透過線條彼此連接。這樣做的目的是——讓工程師在閱讀程式碼時能夠專注在內容、不用額外花費工作記憶來處理流程資訊
Creating a dependency graph can help you understand a piece of complex and interconnected code.
狀態表(state table):以迴圈為例,狀態表會列出一個迴圈功能中所有的變數,並紀錄每一輪、每個變數當下的值。將計算結果紀錄下來,閱讀程式碼時可減低工作記憶的負荷
Creating a state table containing the intermediate values of variables can aid in reading code that is heavy on calculations.