總結
本章旨在介紹「測試食譜(test recipes)」——目的是為了幫助開發者安排測試策略(test strategy),避免測試種類失衡或目標重疊的問題。
測試的層次
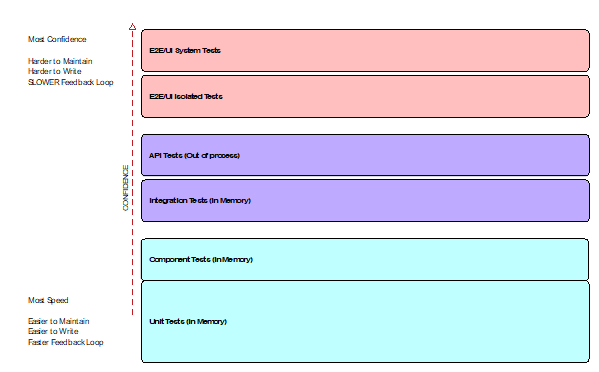
我們可以根據依賴(dependency)的數量來分類測試,由多到少依序是:
- E2E 測試
- 整合測試(integration test)
- 單元測試(unit test)
高層次的測試(E2E)能提供較高的信心加成。低層次測試的優勢則是低複雜度、低脆弱度、好維護以及較快的執行速度。
衡量測試品質的標準
本書透過以下五個標準來衡量測試的品質:
- 複雜度:自然是越低越好
- 脆弱度(flakiness):指的是「會影響測試結果」的不可控因素,越少越好
- 維護性:需要修改測試的頻率(參閱 8 Maintainability),越低越好
- 執行速度:自然是越快越好
- 信心加成:當測試通過時,能增加我們對這包程式碼的信心嗎?增幅越高越好
測試策略的反模式
只有高層次測試
指一包程式碼只有 E2E 測試。缺點非常明顯:
- 因為使用真實依賴,讓測試裡不可控的部分極多,導致測試失敗也不一定代表產品真的有問題,誤報率高(flaky test)
- 執行耗時
- 新增一組測試的成本很高,但帶來的效益偏低,因為腳本之間必定會有重複的流程
本書認為高層次的測試數量應該越少越好,高、低層次測試的比率應該維持在 1: 5 至 1:10 左右即可。
只有低層次測試
指一包程式碼只有單元測試。缺點是——因為缺少「模擬實際使用流程」的測試,所以開發者對於服務「能正常運行」的信心可能不太夠。
目標重複的測試
本書認為高、低層次測試有著相同的測試目標是一種反模式,因為最差的情況是「高層次測試耗時又容易誤報,低層次測試也無法供應足夠的信心」。
We suffer the worst of both worlds: at the top level, we suffer from the long test times, difficult maintainability, build whisperers, and flakiness; at the bottom level we suffer from lack of confidence.
與同事討論後,我們將這個反模式理解為:高層次的測試不該與低層次的測試擁有完全一致的測試目標。
舉個例子:我已經為「處理登入的模組」寫好單元測試,覆蓋一般操作與極端情境。而當我在撰寫 E2E 測試時,我不應該只測試登入模組的行為是否符合預期,而是要將「登入行為」納入 E2E 腳本的一部分,讓這個 E2E 測試驗證「使用者操作整個前端服務的流程」是否符合預期。
透過測試食譜避免反模式
為了避免以上三種測試策略的反模式,本書提出測試食譜(test recipes)的概念,其目的是讓開發者制定出「測試某個功能的最佳組合」。
The idea is to have an informal plan for how a particular feature is going to be tested.
如何執行
在實際開發前,先列出一個單元的使用情境清單。完成清單的標準是,如果一個單元能滿足清單裡的所有情境,你就會對它的功能充滿信心(不會擔心功能疏漏)。
A test recipe represents the list of scenarios that gives its creators “pretty good confidence” that the feature works.
舉個例子——在開發「檢查使用者輸入的內容是否能用來建立帳號」的功能前,我列出了以下測試情境:
- (單元測試)如果傳入「可以建立成帳號的字串」,要回傳 ture
- (單元測試)如果傳入「不可以建立成帳號的字串」,要回傳 false
- (E2E 測試)使用者如果還沒輸入任何內容,不應該回傳任何判定結果
對我來說,該單元只要能針對以上三種情境做出正確反應,它的功能就完備了。這樣就是「完成一個單元的測試食譜」。如果你是遵循 TDD 原則開發的工程師,現在就能根據食譜來撰寫測試。
注意事項
- 建議至少兩人一起規劃測試食譜,用意是為了討論情境是否已經全數列出,以及審視測試層次是否有分配不均的狀況
- 食譜是可以隨時修改的——需求有變時,就要檢查清單中的情境是否還能符合需求
- 食譜盡量以低層次測試為主要成分,因爲執行速度與測試穩健度都比高層次的測試優秀
- 不要重複已經驗證過的情境
補充:部署流程注意事項
部署時,除了執行「一定要全數通過才能發佈」的測試,也需要跑「負責收集數據」的任務(code analysis / complexity scanning / high-load performance testing)。
本書認為這兩大類工作應該各自啟動一個流程(pipeline)執行,不應混雜。理由是——收集數據的任務成敗不應影響部署進行。反之,測試失敗時需要停止後續的發佈工作,但不用為此暫停數據收集。